
Good news! That’s no longer the problem.
The problem now is that we’re too successful.
What?! I hear some of you ask. Don’t you want to be too successful?!
I think I speak for my entire team when I say: hell yes! We want to keep on being too successful. If anything, we want to be even more too successful than we currently are.
But success does present problems. It’s awesome to have thousands of customers and terabytes of data, but then you start dealing with the boring details of questions like where do you put those terabytes of data, and how do you get that data to the customers in a timely manner. And that can be a really tough cookie to crack.
I’m going to be talking about several different aspects of how we’re handling scaling Kiln over the next few weeks, but today, I want to focus on one single narrow thing: caching.
The WISC Stack
The main part of Kiln that you all know and love—the website—is a fairly typical WISC application. We have a couple of web servers running IIS and the Kiln website, which talk to several SQL Server boxes. The nice thing about well-engineered WISC stacks is that, like LAMP, you can scale the databases and the web servers independently. This is the bread-and-butter of designing a scalable application. So far, so good.
The thing is, just adding more SQL boxes isn’t always the answer. If you have complex queries that take a long time to run, then adding another box won’t help anything. It just gives you another box to run your complex query on at the same slow speed. Even if you’re only doing simple queries, adding more database boxes isn’t necessarily the answer. Good SQL boxes are expensive—doubly so if you’re using a big commercial DB package such as SQL Server or Oracle. While you might be able to afford buy more, you don’t want to if you can avoid it.
Instead, you should focus on just not hitting the database in the first place.
The S in WISC
It turns out that there are already some mechanisms we had in place to help with this. We prefetched certain data that we knew we needed nearly every request (like the full list of repositories), and then used that cache for any other lookups during the request. And LINQ to SQL does a bit of its own per-request object caching in certain situations (such as querying an entity by primary key), so we already had some actual data caching going on.
While that kind of stuff can help, what we really wanted to do was to try to avoid talking to SQL at all for common operations. Those complex queries that Kiln does—things like showing the amalgamated DAG for all related repositories—take a long time to run, but the resulting data doesn’t actually change that often. This is a clear and wonderful win, if we can pull it off.
Making it Happen
There were two problems we had to solve: where do you cache the data? and how do you get it there?
The second part was much more difficult. Kiln uses LINQ to SQL for its database access layer. That meant we had a problem: LINQ to SQL is a very complex beast, where objects have a database context that in turn is aware of all the objects that it’s managing. If you just grab a random LINQ object and throw it into Memcache, then it is not going to deserialize cleanly. Throw in that we have piles of custom logic in our LINQ-to-SQL-backed models, and you’ve got a recipe for pain.
We ended up solving this in two different ways:
- We modified our models to allow for detaching and reattaching to the database context. Before serialization, the object is detached, so it has no controlling database context. On deserialization, we attach it to the current context. This isn’t as fast as grabbing an attached object out of a cache (such as the old per-request prefetch cache mentioned earlier), but ends up incurring minimal overhead for the common case.
- We also had to modify our models to know that they might not have come from the DB. We rely heavily on signal handlers to make changes in a given model class propagate to all the parts of Kiln that need to be notified. These were firing erroneously as the deserialization code set piles of properties. The fix we came up with was to suppress signals for deserializing objects—which, since most of our model modifications are done by T4 templates anyway, was very easy to do in a DRY manner.
With these two changes, we were able to reliably store LINQ database entities in Memcache, get them back out, and work with them.
It was easy enough to verify that the number of queries was down, but would the caching code make a real difference?
The Result
I think this graph of what load looks like on one of our DB boxes, before and after the caching deployment, says more than I could in several paragraphs of text:
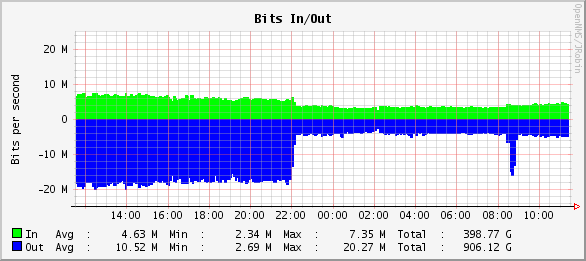
We’ve cut the amount of data we’re getting from SQL by 75%.
The benefits we’re seeing are already impressive. We have faster load times and less DB traffic. But we can still do a lot more: now that we have the outlines of a caching framework, we can continue to profile and to move more of our expensive queries into the cache. Based on what we’ve seen so far, this should yield immediate and real benefits to our Kiln On Demand customers.
Want to comment on this post? Join the discussion! Email my public inbox.